最新版の訓練済みベクトルと訓練用のスクリプトは GitHub で公開しています。
「日本語 Wikipedia エンティティベクトル」は、日本語版 Wikipedia の本文全文から学習した、単語、および Wikipedia で記事となっているエンティティの分散表現ベクトルです。Wikipedia の記事本文の抽出には WikiExtractor を、単語分割には MeCab を、単語ベクトルの学習には word2vec をそれぞれ用いています。
20170201.tar.bz2 (2017年2月1日版, 1.3GB, 解凍後 2.6GB)
20161101.tar.bz2 (2016年11月1日版, 1.3GB, 解凍後 2.6GB)
バイナリファイル (entity_vector.model.bin) とテキストファイル (entity_vector.model.txt) の両方が格納されています。
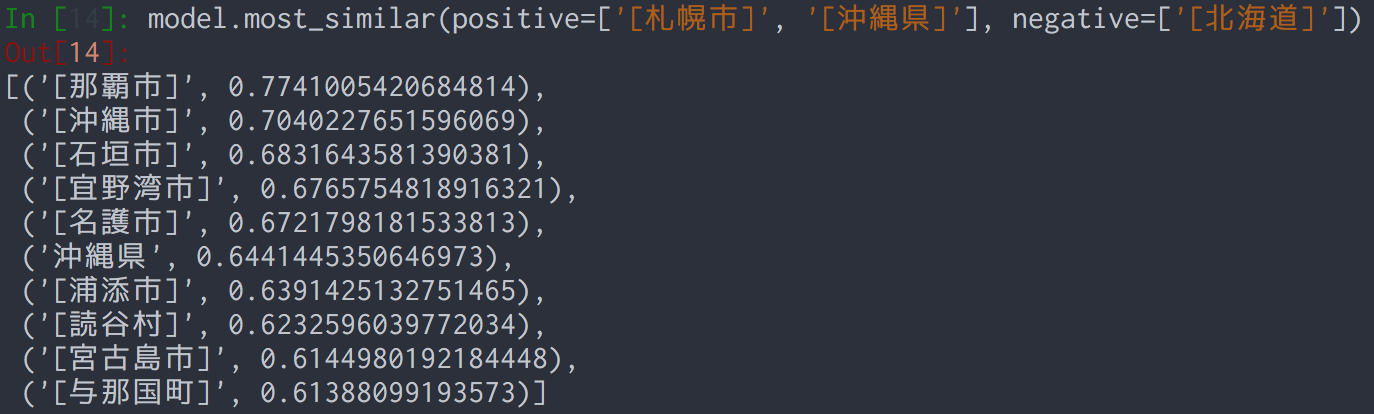
単語の周辺文脈から、単語の意味を表現するベクトルを獲得する手法として、word2vec に実装されている Skip-gram や CBOW などのモデルを用いたものがあります。これらの手法によって学習された単語ベクトルには、「意味が似た単語同士は近い値を持つ」「ベクトル同士の演算によって意味の関係が表現できる」といった、特に意味の計算において有用な性質が見られることがわかっています。
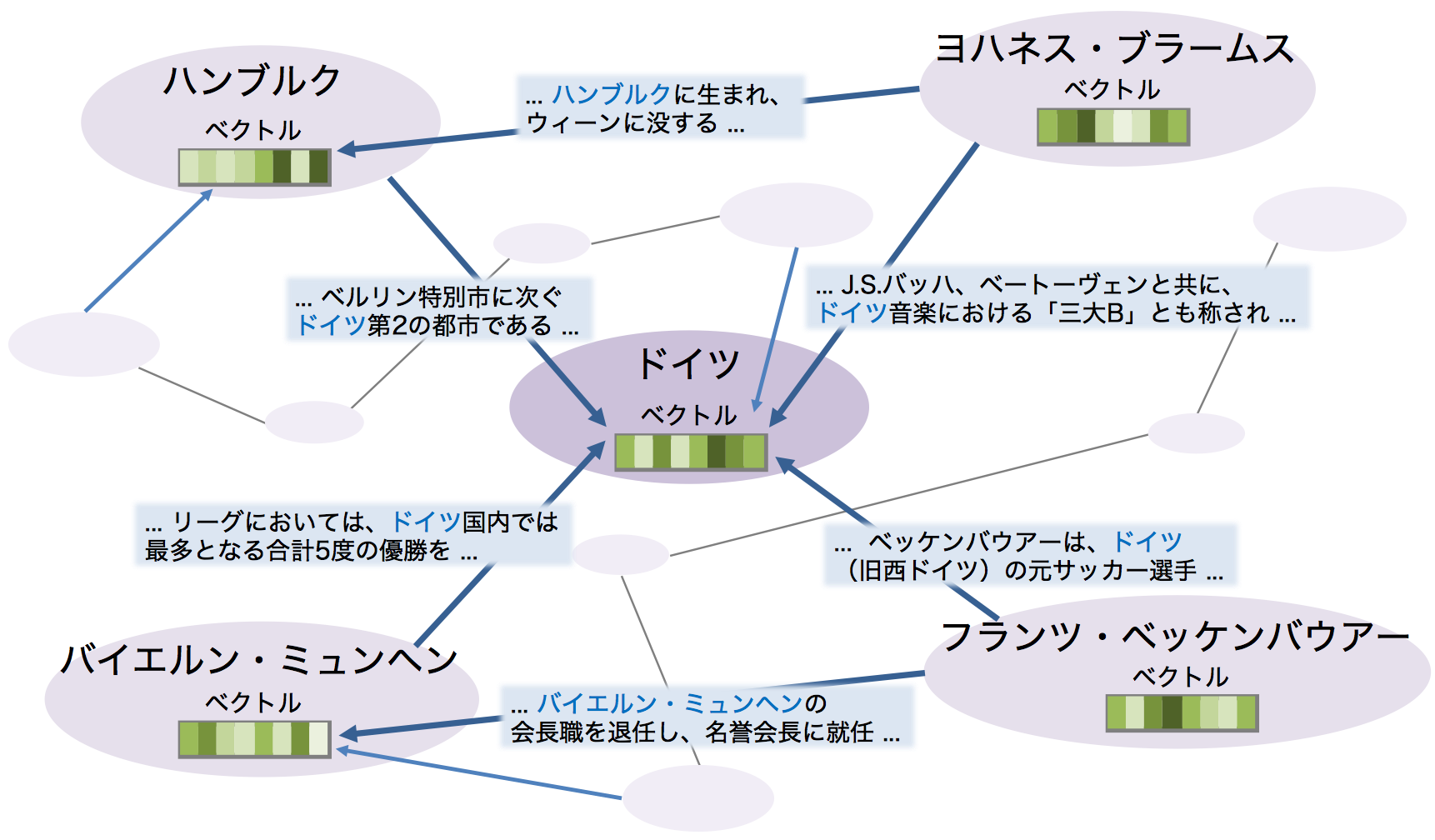
このような手法を一般の単語だけでなく、人名や地名といった、固有表現によって表されるエンティティについても適用しようとすると、文章から固有表現を単語として抽出し、実世界のエンティティに関連づけること(エンティティリンキング)が必要になり、さらに、学習のためには十分な量のデータが必要になります。そこで、我々は固有表現に関する情報を十分に含んだデータとして Wikipedia を利用し、Wikipedia 全記事の本文から、単語のベクトルおよび固有表現によって表されるエンティティのベクトルを、200次元の同一の空間上に学習しました。
Wikipedia の記事となっている固有表現を一般的な単語と区別するため、記事本文中のハイパーリンクを活用しました。
例えば、「ロードレース世界選手権」という記事には以下のような記述が存在します。
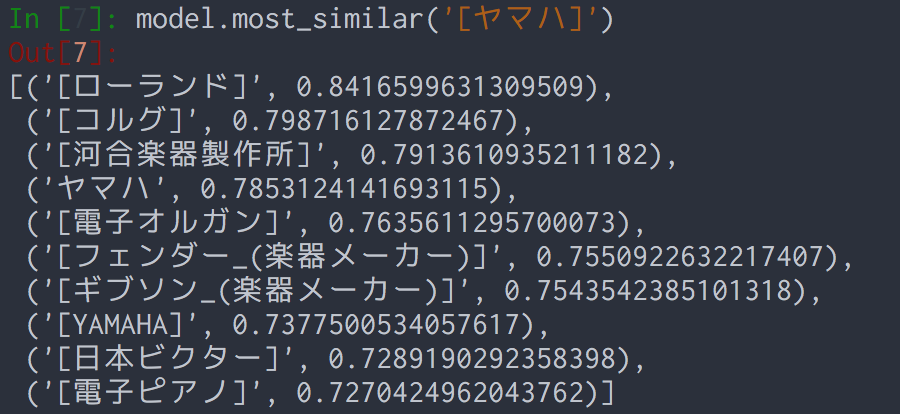
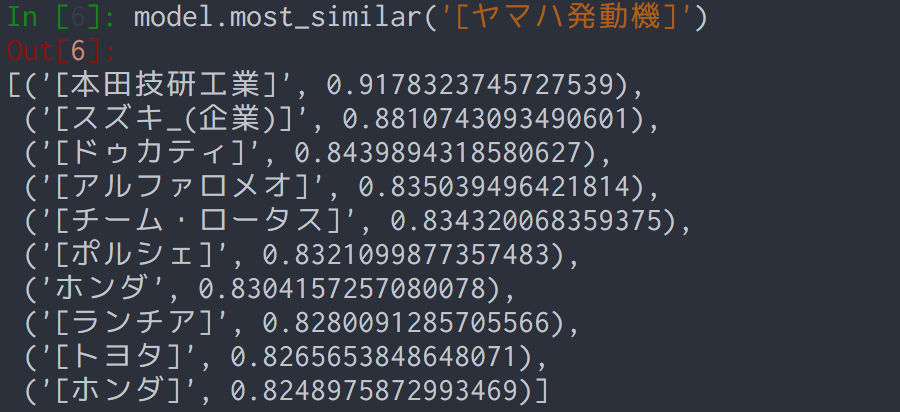
2016年現在出場しているのはヤマハ、ホンダ、スズキ、ドゥカティ、アプリリアの5メーカーと、ワークスマシンの貸与等を受けられるサテライトチームとなっている。
単純にこのテキストから単語の分散表現を学習しようとすると、「ヤマハ」が楽器メーカーのヤマハと区別できなくなったり、「スズキ」が魚類のスズキと区別できなくなってしまうという課題があります。
そこで、「日本語 Wikipedia エンティティベクトル」の構築にあたっては、以下に示すようにそれぞれのリンクのアンカーテキストを「リンク先の記事のタイトル」に置換するという方法を採りました。さらに、[記事名] というようなマークアップを施すことで、通常の単語との区別を行いました。これによって、リンクによって言及されているエンティティを正しく扱えるようにしました。
[2016年のロードレース世界選手権]現在出場しているのは[ヤマハ発動機]、[本田技研工業]、[スズキ_(企業)]、[ドゥカティ]、[アプリリア]の5メーカーと、ワークスマシンの貸与等を受けられる[サテライトチーム]となっている。
また、Wikipedia のガイドラインにもあるように、Wikipedia の記事では、すべての固有表現の出現箇所にリンクがはられるわけではありません。例えば、次の「宝永山」の記事では、「富士山」という固有表現には、最初の出現にはハイパーリンクがはられていますが、2回目の出現にはリンクがはられていません。
宝永山(ほうえいざん)は宝永4年(1707年)の宝永大噴火で誕生した、富士山最大の側火山である。標高は2,693m。この宝永の大噴火以降は噴火していないため、この宝永山が富士山の最新の側火山になる。
このままでは、記事中の固有表現の2回目以降の出現を、ハイパーリンクが貼られているものと同様に扱うことができなくなるので、そのような固有表現の出現に対しても、ハイパーリンクがはられたものと同様にマークアップすることにしました。具体的には、その記事中に出現するリンクのアンカーテキストを記事中から最長一致で検索し、マッチしたものについて、そのリンクのリンク先の記事名に置換しています。
[宝永山](ほうえいざん)は[宝永]4年([1707年])の[宝永大噴火]で誕生した、[富士山]最大の[側火山]である。標高は2,693[メートル]。この[宝永]の大噴火以降は噴火していないため、この[宝永山]が[富士山]の最新の[側火山]になる。
以上の前処理を施したテキストを、MeCab を用いて単語に分割し、word2vec を用いて200次元のベクトルを構築しました。
word2vec での訓練のオプションの設定値は以下の通りです。
| オプション | 値 |
|---|---|
-size |
200 |
-window |
5 |
-sample |
1e-3 |
-negative |
5 |
-hs |
0 |

1. 鈴木正敏, 松田耕史, 関根聡, 岡崎直観, 乾健太郎. Wikipedia 記事に対する拡張固有表現ラベルの多重付与. 言語処理学会第22回年次大会(NLP2016), March 2016.
本リソースの構築は、文部科学省受託研究「実社会ビッグデータ利活用のためのデータ統合・解析技術の研究開発」から部分的な支援を受けて行われました。記して感謝いたします。