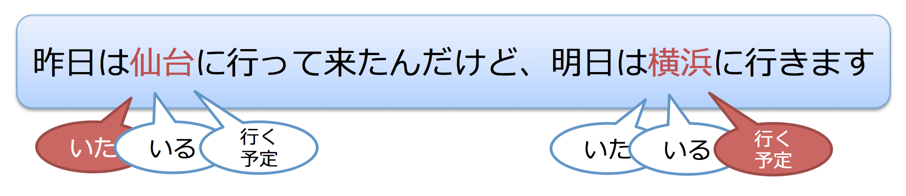
本コーパスは、日本語ツイート内に現れる地名語に対して、ツイートの著者(以下、著者)が「その場に現在いるのか」「いたのか」「行く予定なのか」「言及しているだけなのか」(Liらが文献[3]で Temporal Awarenessと呼んでいる概念と対応)を、ツイートを読んだ第三者がクラウドソーシングを用いて付与したコーパスです。
本コーパスを用いて訓練したモデルは、以下のような応用が考えられます:
以下の10種類のターゲット(地名語)を含むツイート各1200ツイートを元データとし、 Yahoo! クラウドソーシング を用いて以下のようなガイドラインのもとでアノテーションを収集しました。
アノテーションは7名のユーザーが独立に行っています。品質確保のため、日本語話者なら容易に分かるようなテスト設問を15問に1問程度混ぜ、それに正解したユーザーのアノテーションのみを採用しています。
| ラベル | 説明 | 例(対象語:スカイツリー) |
|---|---|---|
Z Present |
現在,対象語で表される場所か,その近くにいる | 間近で見るスカイツリーはきれい |
P Past |
現在,対象語で表される場所にいないが,過去にいた | 週末の思い出は,曇ってるスカイツリーと燃え盛るテーブル |
F Future |
現在,対象語で表される場所にいないが,これから行くつもりであるようだ | 今から スカイツリーへ.下で行くから1時間くらい. |
N Non-Temporal |
対象語で表される場所に言及しているだけで,行く予定があるわけでも,いたわけでもない | スカイツリーって何時から開くんだろ?? |
O Non-Mention |
対象語で表される場所に言及していない | スカイツリーラインの冷風,台風並みに強い |
複数の解釈がありえる場合もありますが、アノテーションのスケーラビリティを優先し、ガイドラインの解釈は各アノテーターにゆだねています。
コーパスは、1行1ツイートの json ファイルとして提供されます。以下にサンプルを示します。本コーパスにツイート本文は含まれません。
{"id_str":"627000677135286272","TA_t":"渋谷駅","TA":["P","P","P","P","Z","Z","Z"],"TA_gold":"P"}
{"id_str":"617101602554445824","TA_t":"病院","TA":["Z","Z","Z","Z","Z","Z","Z"],"TA_gold":"Z"}
{"id_str":"640818043170385921","TA_t":"仙台","TA":["P","N","P","P","N","N","N"],"TA_gold":"N"}
{"id_str":"645938890000347136","TA_t":"清水寺","TA":["P","Z","Z","Z","Z","P","Z"],"TA_gold":"Z"}
{"id_str":"653404437122125824","TA_t":"動物園","TA":["P","P","P","P","P","P","P"],"TA_gold":"P"}
{"id_str":"624001126271053824","TA_t":"改札","TA":["Z","P","P","P","Z","N","P"],"TA_gold":"P"}
それぞれのキーは以下の情報を指しています。
| キー | 説明 |
|---|---|
id_str |
ツイートのIDです。 |
TA_t |
秋葉原, 仙台 渋谷駅等、ターゲットがどれかを表す文字列です。 |
TA |
Z, P, F, N, O のいずれかの値を持った7要素の配列です。 |
TA_gold |
5人一致をラベル認定基準とした場合のラベルです。 |
現時点では、以下のような制限があることをご承知ください.
ツイート本文は含まれません : Twitter APIの利用規約によりツイート本文の再配布が禁止されているため,データにツイート本文は含まれません.コーパス利用者は,Twitter APIを利用して,id_strフィールドの情報をもとにデータを復元する必要があります.これにはそれほど難しいプログラミングが必要とされるわけではありませんが,データの入手が困難な方はお問い合わせください.ただし,非公開アカウントになったユーザーのツイートや,削除されたツイートのデータが正しく復元できない可能性もあります.
Train / Dev / Test の分割は仮のものです。学習されたモデルの客観性を担保するためのより妥当な方法を検討しています。
93%のツイートにおいて7人中5人の一致が取れる、比較的妥当なガイドラインであることが分かっています。
| 合計ツイート数 | 12318件 |
|---|---|
| 7人一致 | 2212(18%) |
| 6人一致 | 5452(44%) |
| 5人一致 | 3797(31%) |
92%のツイートに対して O 以外のラベルが付与できたことが分かっています。
| ラベル | 5人一致を基準とした場合のデータ数 |
|---|---|
Z |
2413(20%) |
P |
2342(19%) |
F |
2134(17%) |
N |
4416(36%) |
O |
962(8%) |
複数の実験設定が考えられますが、ここではTA_goldを正解として、同梱されている Train/Dev/Test splitに基いて訓練データ全てを学習に用いる設定(インドメイン設定)において我々が構築したモデルの現在の性能の目安を示します。詳細は文献[1]をご参照ください。
データに関するお問い合わせは 松田 耕史 (Koji Matsuda) < matsuda at ecei.tohoku.ac.jp > までお気軽にお寄せください.
本コーパスを利用した研究成果を発表される際は,以下の文献を参照いただけますと幸いです.
本コーパスの構築は、文部科学省受託研究「実社会ビッグデータ利活用のためのデータ統合・解析技術の研究開発」、及び文部科学省科研費(15H01702, 15H05318)から支援を受けて行われました。記して感謝いたします。
